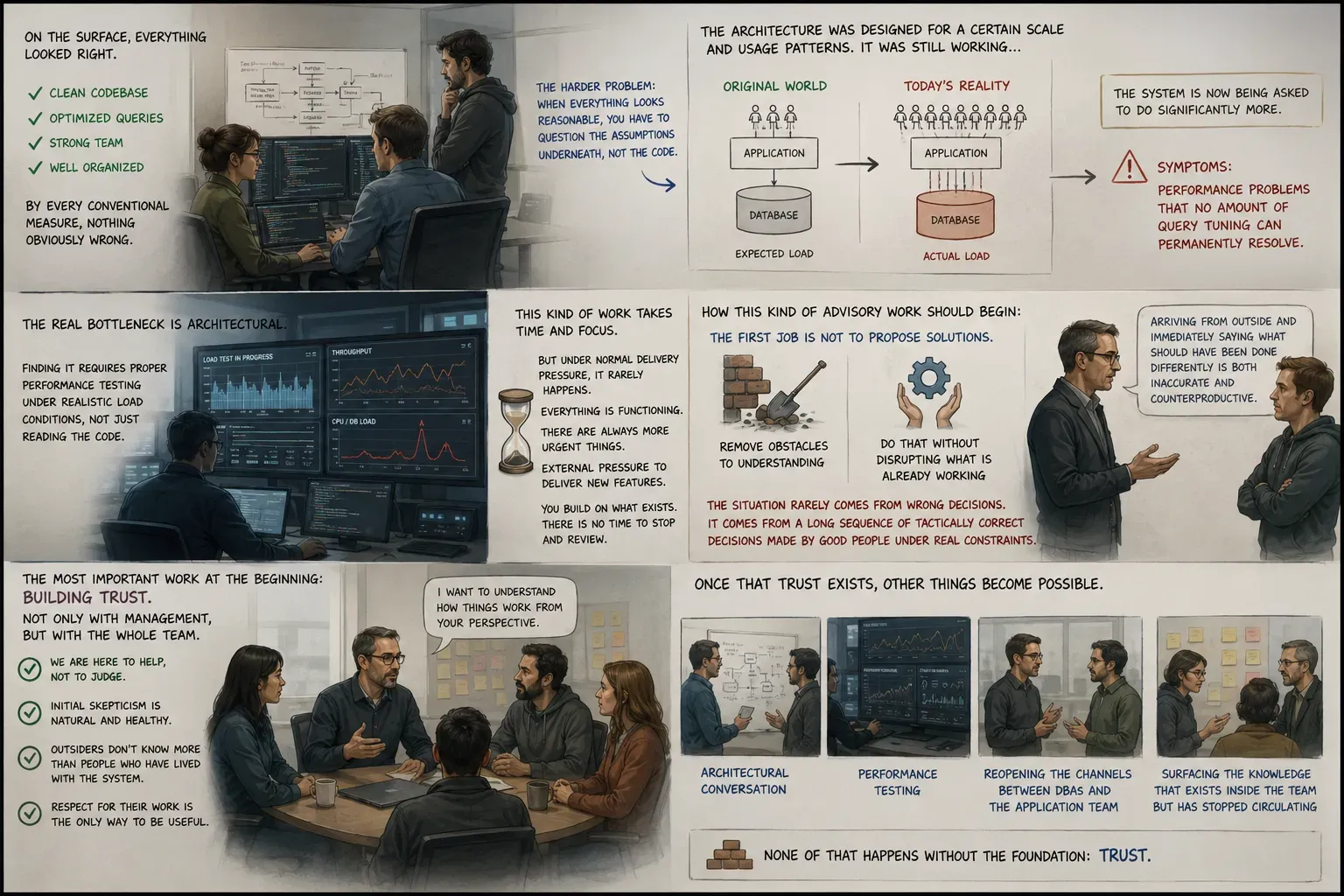
When I first looked at the system, I could not find anything obviously wrong. The codebase was reasonable, the queries were not doing anything terrible, and the team clearly knew what they were doing. That is actually the harder situation to walk into.
When the code is messy, you know where to look. When everything looks reasonable, you have to question the assumptions underneath the code, not the code itself.
What we were dealing with was an architecture that had been designed correctly for a certain scale and a certain set of usage patterns. It was still working. But the system was now being asked to do significantly more than it was originally designed for, and the symptoms were showing up as performance problems that no amount of query tuning could permanently resolve.
My suspicion was that the real bottleneck was architectural. But that is exactly the kind of claim you cannot just make in a room and expect people to accept. It had to be demonstrated with proper performance testing under realistic load conditions, not just argued from reading the code. The testing had a dual purpose: on one hand, to find and fix what could be improved right now, with tactical changes that would produce immediate results. On the other, to show, with data and not opinions, that the space for purely tactical optimizations was running out fast, and that the next level of improvement required a different kind of conversation about the architecture itself.
That kind of work takes time and focus. It is the kind of work that a good team under normal delivery pressure never quite gets to, because everything is still technically functioning and there are always more urgent things to attend to. And on top of that, there is always external pressure to deliver new features. You build on what exists. There is no time to stop and review.
Something else is worth saying about how this kind of advisory work should begin. The first job is not to propose solutions. It is to remove obstacles to understanding, and to do that without disrupting what is already working. The situation rarely comes from wrong decisions. More often it comes from a long sequence of tactically correct decisions made by people who were doing their best under real constraints. Arriving from outside and immediately suggesting that things should have been done differently is both inaccurate and counterproductive.
The more important work at the beginning is building trust, and not only with the management that brought you in. The whole team needs to feel that you are there to help, not to judge. It is entirely understandable, and in fact healthy, that there is some initial skepticism. Who are these people coming from outside, thinking they know better than us? That skepticism is largely correct. Someone arriving from outside cannot know more than the people who have been living with a system for months or years. Moving with genuine respect for that work is the only way to actually be useful.
Once that trust exists, the other things become possible: the architectural conversation, the performance testing, reopening the channels of communication between the DBAs and the application team, surfacing the knowledge that exists inside the team but has stopped circulating. None of that happens without the foundation.